

Why campaign execution breaks differently across regions

Retail campaign performance varies across regions, but teams often lack clarity on where execution breaks.
Similar campaigns produce different outcomes, yet the breakdowns do not occur uniformly. They shift across regions, stores, and time windows.
In some regions, campaigns are activated later than planned. In others, execution is incomplete despite timely rollout. In a few, campaigns are visible but not actively driven on the floor. These differences are rarely captured in a consistent way.
Clear visibility into where execution diverges is critical for managing campaign performance across regions.
Why campaign outcomes vary by region?
Central teams often design campaigns with a one-size-fits-all approach, assuming stores are broadly similar in capability, readiness, and operating context. This simplifies planning, but execution varies because stores differ in ways that directly affect delivery on the ground.
These differences show up at specific stages of campaign execution:
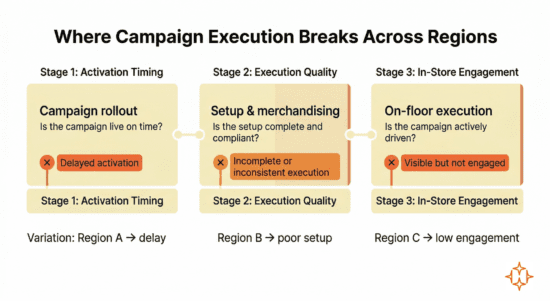
These variations create distinct execution gaps across regions, even when planning and intent remain consistent.
Many retailers think it’s the customer
When campaigns underperform in certain regions, the default explanation often points to customer behaviour. Differences in demand, preferences, or price sensitivity are frequently cited.
Internal reviews across retail networks, however, show that execution-related factors account for a significant share of regional variance. Delayed rollout, incomplete setup, missing POSM, inconsistent merchandising, and limited staff readiness all affect how campaigns are delivered on the ground.
These factors do not always appear together or in a consistent way across regions. As a result, performance differences are often interpreted without a clear view of how execution actually varied.
In many cases, when execution quality is normalized, regional performance gaps narrow significantly. This indicates that customer behaviour is more consistent than assumed, while execution conditions are not.
Why traditional reporting falls short
Most campaign reporting focuses on outcomes such as sales uplift, conversion, or ROI at a regional level. These metrics indicate where performance differs, but they do not provide a clear view of how execution varied across stores.
When performance gaps appear, teams look for supporting signals across available inputs:
- Store images
- Activation updates
- Audit notes
- Internal communication threads
These signals exist, but they are not structured or reviewed together in a consistent way.
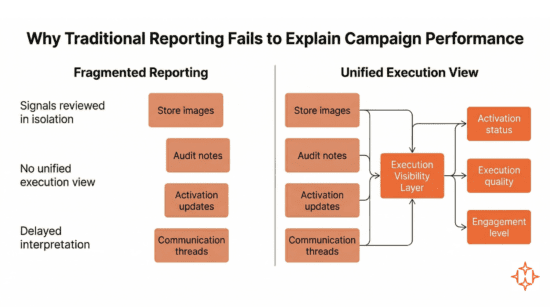
As a result, key aspects of execution are assessed in isolation. Activation status, execution quality, and in-store engagement are not connected, making it difficult to understand how they collectively influence performance.
This creates a gap at the point of analysis. Performance differences can be observed, but the underlying execution patterns remain fragmented.
| Challenge | What it means in practice |
| Fragmented signals | Execution inputs are reviewed separately |
| No unified view | Activation, setup, and engagement are not connected |
| Delayed interpretation | Issues are identified after impact |
| Inconsistent comparison | Regions are not evaluated on the same execution parameters |
Without a unified view of execution, post-campaign reviews remain broad, and corrective actions are based on partial visibility rather than clear diagnosis.
How AI and visual evidence bridge the execution gap
What is required is a consistent way to capture and evaluate execution signals across stores and regions.
A consistent view of execution requires signals that can be captured, validated, and compared across stores in the same way.
Visual evidence provides a structured way to observe execution at the store level. Store images, when captured in a defined format, make it possible to verify whether campaigns are live, whether setup aligns with guidelines, and whether merchandising is consistent across locations.
AI enables this validation to be applied uniformly. Execution can be assessed at scale, making it possible to identify where activation is delayed or where setup is incomplete without relying on manual review.
Camera analytics extend this further by adding continuity. They provide visibility into whether campaign zones are staffed, how consistently they remain active during store hours, and how customers engage with them over time.
These inputs bring together the key dimensions of execution:
- Activation → whether the campaign is live on time
- Execution quality → whether setup is consistent
- Engagement → whether the campaign is actively driven
When these signals are structured and evaluated together, execution differences across regions become directly comparable.
| Signal | What it indicates | Decision enabled |
| Visual validation | Campaign live or not | Identify activation gaps |
| Setup consistency | Compliance with guidelines | Detect execution issues |
| Staff presence | Coverage in campaign zones | Adjust staffing |
| Customer interaction | Engagement levels | Improve in-store execution |
Teams can now observe execution differences with greater clarity:
- Which regions activated campaigns on time
- Where execution quality dropped despite timely rollout
- How staff presence and customer engagement varied by location
- Which deviations were isolated and which were systemic
This creates a shift from outcome-based reporting to execution-based visibility, allowing teams to identify gaps earlier and respond with more targeted actions.
Execution no longer needs to be inferred from outcomes. It can be observed, measured, and compared directly
Conclusion
Campaign performance across regions depends on how consistently execution is delivered at the store level. Differences in outcomes often reflect variations in activation, execution quality, and in-store engagement that are not clearly observed or compared.
As campaigns scale, the ability to capture and connect these execution signals becomes essential. Without this, performance gaps remain difficult to diagnose, and corrective actions rely on partial visibility.
A structured view of execution enables teams to compare regions on the same parameters, identify gaps earlier, and act with greater precision.
About HipHip.AI
HipHip.AI is an AI-powered, end-to-end retail execution platform used across 10,000+ retail brick and mortar stores. It unifies inventory, merchandising, campaign management, store teams, and store spend into a single operating system—enabling real-time visibility and execution across stores.
Core capabilities include:
- Inventory Replenishment
- Visual Merchandising
- In-Store Campaign Management
- Camera Analytics
- Shelf Analytics
- Sales Analytics
- Helpdesk
- Task Manager
- Rostering & Attendance
- Spend Management
- Incentive Calculator
- New Store Opening
- Learning & Development
- News Flash & Communiqué
- Net Promoter Score
- Franchise Orders
- In-App Chat & Robo Calls
- Gamification & Leaderboard
HipHip.AI integrates seamlessly with existing POS, ERP, WMS, and HRMS systems, ensuring zero disruption to current infrastructure while unlocking smarter, faster retail execution.
Talk to an expert → hiphip.ai
Frequently asked questions
- How can teams distinguish between demand-driven performance gaps and execution-driven gaps?
Performance gaps should be evaluated alongside execution signals. When activation, setup, and engagement vary, outcomes are influenced by execution. When these are consistent, remaining differences are more likely demand-driven.
- Why is it difficult to identify execution breakdowns using existing reporting systems?
Execution signals exist but are fragmented across formats and systems. Without a unified view, it becomes difficult to connect execution gaps with performance outcomes.
- Which execution dimension has the highest impact on regional performance variation?
Activation delays and inconsistencies in execution quality typically create the largest gaps. Engagement becomes critical in campaigns requiring active in-store interaction.
- How does real-time execution visibility change decision-making?
It shifts teams from post-campaign analysis to active intervention, enabling earlier identification of gaps and more targeted actions during the campaign.
- What are the risks of relying only on outcome-based campaign evaluation?
It can mask execution variability and lead to incorrect conclusions about demand, resulting in misaligned decisions and repeated execution gaps.